
AIB Section 2 머신러닝 프로젝트
섹션 리뷰 기간 동안 배운 내용 다 정리하고 나서 프로젝트도 간략하게 정리해보려고 한다. 우선 프로젝트는 간략하게 다음 단계로 구성된다: 문제 정의 (주제, 분류/회귀), 데이터 수집, 모델링에 맞도록 데이터 정제, 모델링, 결과로 인사이트 확인 및 모델 개선, 사용여부 결정.
내 마음대로 정하는 주제
섹션 1은 첫 프로젝트이기도 해서 토픽과 문제가 주어졌었지만, 섹션 2부터는 스스로 도메인도 정하고 주제도 정하고 모든 것을 정하게 된다. 물론 섹션에 걸맞는 결과를 내놓아야 한다. 맘대로 할 수 있다는게 매력적임과 동시에 참고할 만한 것이 없다면 맨땅에 헤딩하는 격이 될 수도 있다. 난 섹션 2에서 한 번도 다루어보지 않은 멀티클래스 분류 문제를 선택했고, 참 많은 시간을 할애해야 했다. 물론 주말에는 적극적으로 게을러지기 때문에 주말동안 아무것도 안 한 내 잘못도 있긴 했다. 그래도 썩 나쁘지 않은 결과를 냈으니 다음에 더 열심히 해봐야지.
아무튼 내 도메인은 헬스케어로 정했다.
처음 문제 정의
주제를 마음대로 정할 수 있지만, 데이터도 함께 찾을 수 있어야 한다. 처음에는 원인을 명확하지 않은 통증의 원인들 알아보기라는 주제로 구글, 캐글, 또는 챗GPT로 내가 분석하고 싶은 데이터를 찾아보고자 했었다. 그런데 데이터를 찾아보기 어려웠고, 또 주제를 다시 분석하는 도중 머신러닝 문제가 아니게 된다는 것을 파악했다. 원인을 알 수 없다는 것은 정상적인 범주 내의 생활을 하고 있다는 것이고, 그 정상 범위는 매우 좁다. 그러면 .sort_values()로 바로 끝나게 된다. 이래서 순차적으로 하는 것이 제일 중요하다. 만약 문제를 면밀히 살펴보지 않았다면 이번 프로젝트는 망했을 것이다.
다시 문제 정의
내가 무엇을 가지고 검색했는지는 전혀 기억은 나지 않는데, 캐글에서 흥미로운 주제를 찾았다. Exercise Pattern Prediction이라고 운동 자세를 예측하는 주제이다. 오랜 기간동안 피티를 받고 있고 내 자세가 안 좋은 부분은 자각하고 있어서 그런지 참 와닿는 주제였다. 그런데 소스 링크는 다운되어 있고, 설명은 매우 빈약했다. 그래도 대충 알아보고 할 수는 있었는데, 프로젝트 기간 시작 전 디스커션에서 같은 조의 정말 좋으신 분이 백업 링크가 있는 자료를 찾아주셨다. 그래서 실제 소스를 찾게 되었다: Human Activity Recognition. 이제 알고보니 캐글에 있는 데이터는 원데이터로 만든 가짜 데이터였다. 조원 분 감사합니다.
그래서 왜 데이터를 이야기하는가 하면, 사실 데이터를 먼저 찾고 나서 문제 정의를 하게 되었다. 물론 프로젝트 다 마치고 나서 보면 주제도 헬스케어 안에 매우 적합했고 좋은 결과를 냈긴 했다. 하지만 문제를 의식하고 나서 데이터를 찾아야지, 내가 할게 없어서 데이터를 찾고 돌아다니는게 조금 이상했다. 얼른 web crawling을 배워서 내가 찾고 싶은 데이터를 뽑아낼 수 있기를.
문제 정의는 이것이다. 스마트 웨어러블이 자세에 대한 정보를 주지 않고, 개인에 알맞은 자세를 고려하지 않는 무조건 따라하세요의 홈트레이닝, 그리고 지출이 엄청 세고 신체접촉이 불안한 홈트레이닝의 단점을 보완할 센서/머신러닝 모델을 개발할 수 있을까? 이래놓고 보니 내가 피티 받는게 웃기긴 하다. 아직 내가 범용 센서를 개발 못 해서 그런거라고 치자.
EDA
사실 내 데이터는 연구 목적으로 수집된 데이터기 때문에 EDA를 크게 진행할 것은 없다. 2.5초마다 자동적으로 기록되는 평균값이나 통계치 칼럼을 제거하니 결측치도 하나도 없었다. 모델 해석하고 성능 향상을 위해 특성 중요도를 보고 필요 없는 칼럼 제외하는 것도 미리 생각해보았는데, 어려울 것이라는 생각이 동시에 들었다. Drop-column importance를 해야하기 때문이다. 왜? 내 데이터는 특성들끼리 상관관계가 매우 크기 때문이다. 허리, 팔, 전완, 덤벨 다 연결되어 있는데 움직인다고 하면 상관관계가 당연히 크다. FI (Mean Deacrease in Impurity)는 noise한 데이터의 중요도를 높게 산다. Permutation Importance와 Partial Dependency Plot은 상관관계가 높은 데이터에 대해 비현실적인 분석 결과를 준다. 그래서 여러 칼럼을 동시에 드롭하는 DCI를 해봐야 할텐데 칼럼은 너무 많고 내가 경험이 적고 또 주어진 기간은 3.5일이므로 특성을 들여다볼 시간 없겠다고 생각이 들었다.
그래서 대신 무엇을 할 수 있을까 하는 고민에서 움직임 한 번을 구분해보자는 생각을 했다. 하나의 자세로 운동할 때 피실험자는 10번 덤벨을 들었다고 한다. 그래서 그래프로 확인하면 10번의 움직임을 포착할 수 있다.

위젯으로 그래프에 마우스 올려놓으면 그 위치 정보를 알 수 있다. 이렇게 10번의 움직임을 구분하고 10을 가지고 train_test_split을 했다. 코랩이 위젯 환경이 참 안 좋다고 한다. 쥬피터와는 달리 별도로 third-party app 사용하겠다는 선언도 해야되고 말이다. 아무튼 문제 없이 분리.
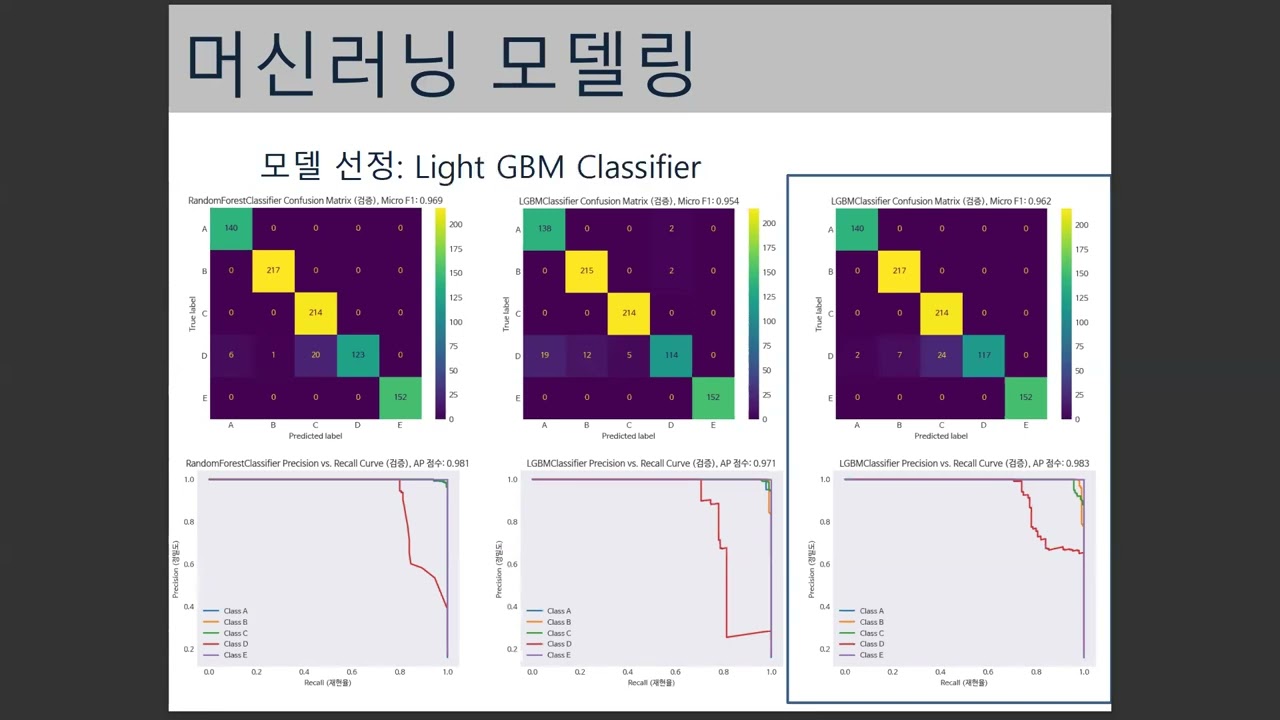
멀티클래스는 어떻게
나는 남들 하는 만큼 하고 그보다 조금 더 잘 하면 된다는 생각으로 사는데, 멀티클래스를 안 배워봐서 전혀 비교할 수 없었다. 물론 접근 방식은 똑같은데, 평가지표 선택이나 임계값 조정이 매우 달랐다. scikit-learn의 평가지표는 숫자로 표기되는 것들은 binary와 마찬가지로 그냥 넣으면 잘 값이 나오는데, ROC나 P-R은 각각의 클래스에 대해 구해야 한다. 라이브러리 업데이트 해줬으면 좋겠다.
아무튼 약간의 불균형이 있는 데이터였고 또 각각 클래스에 대해 ROC나 P-R 구한다면 하나의 클래스 대 나머지 클래스라서 어차피 불균형 생긴다. 그래서 불균형에 기왕 구할거면 제대로 해보자 하고 OneVsRestClassifier를 이용해보았다. 그렇게 얻은 P-R 그래프

임계값은 어떻게
여러 자료들 찾아보았는데, multiclass/multilabel을 동시에 다루어 .predict_proba()로 임계값보다 큰 것을 얻는 것은 많다. 그런데 그건 각각의 확률에 대해 True/False가 가능하기 때문에 멀티레이블 문제가 되버린다. 아마 multiclass만 다루어 임계값 조정하는 것이 구현된 라이브러리는 없을 것이다. 링크 1을 보면 One Vs. Rest Classifier 알아보라고 하는 답변과 binary로 접근해서 클래스 하나 선택하라는 답변이 있다. 나머지도 다 마찬가지. 찾을 수 있는 것 전부 찾아봤지만, 멀티클래스에서 임계값 조정 안 한다. 그냥 ROC나 P-R AUC 보고 마는 정도이다. 나중에 찾게 되면 업데이트 하겠지만 내가 알기로는 멀티레이블이 아닌 멀티클래스 임계값 조정은 없음.
실수를 줄여보기
머리 잘 안 돌아가고 시간 부족하면 함수 하나 큰거 만들어서 반복해서 쓰는 습관이 있다. 하나씩 제대로 살펴보고 조정해야 정밀한게 나올텐데 그럴 시간이 없음. micro F1과 micro AP 점수는 다 이미 평균 개념이 들어가 있다. 그런데 나는 시각화에 평균 micro F1 / 평균 micro AP라고 표기했다. 그리고 발표 PPT에 검증을 보여줘야 하는데 훈련 보여준게 있다. 그거 훈련 결과 따로 내고 검증 결과 따로 냈으면 실수 안 했을 거다. 하나로 묶어서 보여주니, 발표 당일 아침 피피티 만드는데 당연히 헷갈렸다. 코드를 divide and conquer. 필요한 건 나누고 그렇지 않으면 그대로 둬야됨.
발표 시간이 짧고 말이 너무 빠르다
코드스테이츠의 프로젝트 발표 시간은 10분이다. 그런데 체크리스트는 분명 10분 초과하게 된다. 청자가 데이터 문외한이라 가정하면 내가 사용하는 용어 전부 다 정의해줘야 하는데, 거기에 문제 정의부터 해석까지 빠짐 없이 한다? 10분 초과임. 시간 채점 기준이 많이 이상하다. 그래서 충청도인 내가 평소의 3배 속도로 말을 했고, 피드백 조원들이 말이 너무 빠르다고 했다.
다음 프로젝트에선 코드스테이츠 점수 신경 안 쓰고 20분동안 발표하거나, 10분짜리에 필요한 부분만 넣어봐야 겠다. 만약 10분짜리에 걸맞는 발표영상이었다면 이번 프로젝트는 문제정의, 데이터 수집경로, 모델링 결과, 모델해석, 한계점으로 구성되었을 것이다. EDA, EDA 중 가설 확인, 기준모델 설명할 시간이 없다. 내일 섹션 만족도조사에 이거 입력해야겠다.
피피티 예쁘게 만들기
시간이 없어서 대충 만들 수밖에 없었지만, 시간분배를 더 잘했다면 예쁘게 만들 수 있었을 것이다. 황금같은 주말이지만, 다음 프로젝트 때는 조금 더 신경 써보자.
댓글남기기