
AIB 딥러닝 323 언어모델, Recurrent Neural Network
직전에 배운 Word2Vec은 일종의 언어 모델이다. 언어 모델은 문장에서 단어 순서에 그 단어가 들어올 확률을 계산해내는 모델이다. CBoW로 생각하자면 $ P(w_c | w_c-2, w_c-1, w_c+1, w_c+2) $이다.
기존의 통계적 방법은 문장 첫 단어부터 given에 넣고 시작하며, 첫 번째 포스트에서 언급했듯이, 한 단어씩 학습하고 넘어갈 때 그 위치에 들어올 단어를 학습하지 못했다면 그 단어를 포함한 문장을 만들 수 없다. 예를 들어 “나는 엄청 배가 고프다”와 “나는 매우 배가 고프다”만 학습했다면 “나는 무지 배가 고프다”를 출력할 수 없다. 이를 희소성의 문제라고 한다.
희소성의 문제를 애초에 생각할 필요가 없는 방법으로 Word2Vec과 fastText가 있었다. 비슷한 위치에 비슷한 뜻의 단어가 위치하기 때문이다.
그렇다면 이를 이용해서 실제로 문장을 출력하기 위해서는 어떻게 해야 하는지를 배워보자.
Recurrent Neural Network(RNN)의 Recurrent는 순환을 의미한다. 일반적인 퍼셉트론에서는 이전 층의 노드들이 전부 가중치로 곱해져 들어올 것이 여기서는 iterate 순간의 단어와 이전 노드의 결과가 가중치로 곱해져 들어온다. 출력이 다시 입력되는 것이 순환인 것이다. 활성화함수는 tanh가 사용된다.
RNN의 종류는 one-to-many, many-to-one, many-to-many가 있다.
- one-to-many: 이미지를 받아서 캡션 (one sequential vector) 생성 가능 → Image captioning
- many-to-one: 문장을 입력받아 감정 수준 파악 → sentimental analysis
- many-to-many
- machine translation / seq2seq: 번역할 문장을 입력 받아 번역된 문장을 내놓는데, 여러 입력을 거친 순간부터 출력을 만들어내어 은닉층의 iteration은 입력이나 출력 데이터 수와 일치하지 않는다.
- 입력 받는 즉시 출력 시작
RNN은 간단하지만 순차적으로 계산하기 때문에 병렬화가 되지 않아서 느릴 수 있고, 또 문장이 길어지면 tanh 입력 과정에서 기울기 소실이 계속 반복된다. 이를 기울기 폭발이라 부른다. 기울기 정보를 별도로 유지시키는 방법으로 LSTM이 있다.
LSTM: Long term short memory. 장단기기억망. 이전 정보를 잊어버리지 않기 위해서 기존 RNN에 cell state를 추가한 것이다. 이 cell state 자체는 활성화함수를 거치지 않는다. 대신 cell state와 hidden state의 정보를 주고받기 위해 세 개의 gate가 추가된다.
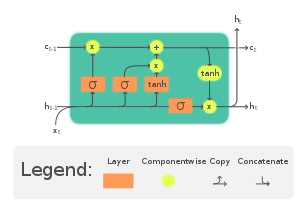 https://en.wikipedia.org/wiki/Long_short-term_memory |
- forget: 과거 정보를 얼마나 유지할지 결정해서 cell state에 곱한다. 곱셈의 크기에 따라 크면 많이 유지하고, 작으면 어느 정도 소실시키는 것이다.
- input: 새로운 정보를 얼마나 활용할지에 대한 것이다. cell state에 그 정도를 더해준다.
- output: 업데이트 된 cell state에서부터 정보를 받아와서 출력으로 낸다.
이를 더 간단하게 만든 GRU도 있다. Gated Recurrent Unit. cell-state는 없지만 직전 hidden-state에서부터 두 가지의 반-병렬 연산을 때문에 cell state의 역할과 hidden state 역할 둘 다 있다.
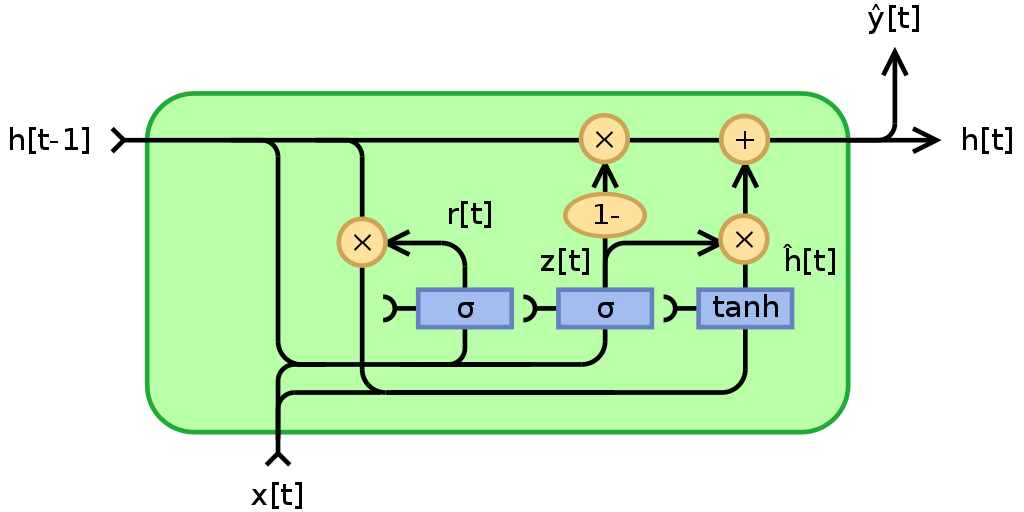 https://en.wikipedia.org/wiki/Gated_recurrent_unit |
- update z: 이전 정보를 얼마나 통과시킬지. 직전 hidden state에서 들어온 값으로 z를 계산하는데, z가 1이면 forget, z가 0이면 input만 열린다.
- reset r: 이전 정보를 얼마나 잊을지. 직전 hidden state에 들어온 값에 잊을 정도를 곱해주고, 이것을 현재 입력과 concat해서 tanh에 입력시킨다.
코드로서는 tf keras의 layer 안에 LSTM와 GRU layer가 있다.
tf.keras.layers.LSTM(
units, # hidden state의 size인 `units`를 입력할 수 있다.
activation='tanh',
recurrent_activation='sigmoid',
use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros',
unit_forget_bias=True,
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0, # input에 대해
recurrent_dropout=0.0, # recurrent output/input에 대해
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
time_major=False,
unroll=False,
**kwargs
)
tf.keras.layers.GRU(
units,
activation="tanh",
recurrent_activation="sigmoid",
use_bias=True,
kernel_initializer="glorot_uniform",
recurrent_initializer="orthogonal",
bias_initializer="zeros",
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
time_major=False,
reset_after=True,
**kwargs
)
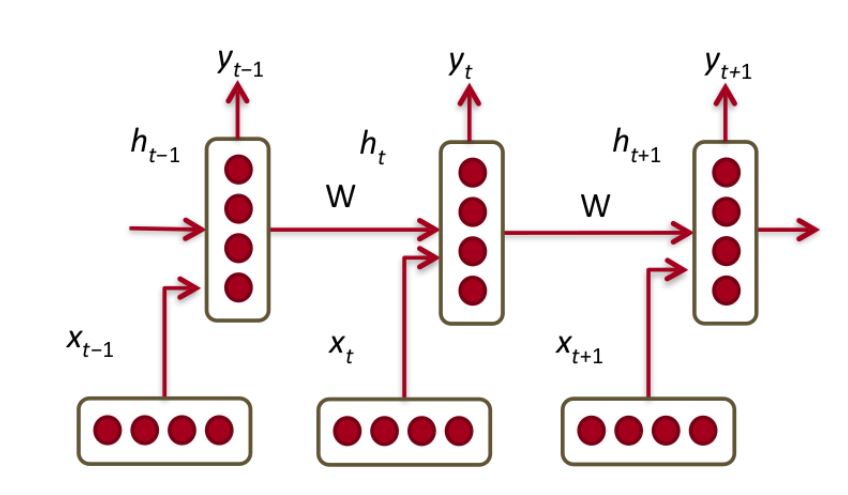 https://datascience.stackexchange.com/questions/12964/what-is-the-meaning-of-the-number-of-units-in-the-lstm-cell |
Attention은 다음 포스팅에 다룰 예정.
댓글남기기