
AIB 데이터 엔지니어링 섹션 4 스프린트 1 랩업
wrap-up
- 이번 스프린트를 왜 배웠을까. 모델을 만들고 데이터를 다루기 위해서 작업 환경 구축. 협업하는 방법 배우기
- 터미널: 컴퓨터와 소통하기 위한 창구로 키보드로 문자 입력
- 가상환경: 프로젝트 수행 중 충돌을 방지하기 위해 만든다.
- 깃: 협업. remote upstream에서 remote downstream으로 fork해서 local 상 (branch에서) feature 개발 후 add, commit으로 local git에 반영, push downstream (origin)으로 remote downstream에 반영, 마지막으로 remote upstream으로 pull request
- sql/db: large data를 관리하기 위해. 여기에 관리하는 언어가 sql.
- DBAPI: 개발 언어와 db/sql을 언결. connection → cursor → close
- on-premise: 속도, 보완의 장점
- cloud: 관리성, 간편성
- 관계형 데이터베이스: 정리가 된, 구조화된 데이터를 저장한다. json을 자주 본다. 딕셔너리랑 비슷하긴 한데 섞여 있는 부분이 많아서 정형화되어 있다 보기 어렵다. 정형 데이터는 관계형 데이터베이스에, 나머지는 파일서버에 저장
- 데이터 레이크/data lake: 데이터 상태 중 원 상태. 정제 전 상태 이를 정제하고 사용하게 된다.
- 데이터 웨어하우스: 데이터를 정제된 상태로 저장. 데이터 분석을 위해 모음
- 데이터 마트: 그 정제된 것을 필요에 따라 나눈 것. 최종 사용자에게 필요한 것으로 나눔.
- 트랜잭션: 거래에 필요한 부분이 데이터베이스로 의미가 확장되어 용어를 사용함. ACID가 보장된 process.
- OLTP online transaction processing: 조회; OLAP: 데이터 분석을 위한 것.
- ETL Extract-transform-load: 추출하고 변환하여 적재한다; ELT: 순서 바꿈 변환 후 읽을지, 읽은 다음 변환할지에 대한 부분이다. 사용자가 바로 사용하기 위해서는 ETL
추가 배울 내용
- 3층 스키마 (보는 관점)
- 함수 종속, 정규화, 키 종류 (슈퍼, 후보, 기본, 대체, 외래)
- DB 옵티마이저
- DB 인덱스
- csv 다루기
- B-TREE 자료 구조
3층 스키마
스키마를 복기해보면 데이터베이스 구조에 대한 설명이다. 3층 스키마는 실행 프로그램과 실제 데이터베이스를 구분해놓는다. 3 단계로 구분할 수 있는데, External/View/외부, Conceptual/Logical/개념, 그리고 Internal/Physical/내부 layer이다. 이를 통해서 데이터의 독립성을 확보한다. 즉 하나의 단계에서 데이터가 변한다고 해서 다른 단계에 영향을 미쳐서는 안 된다.
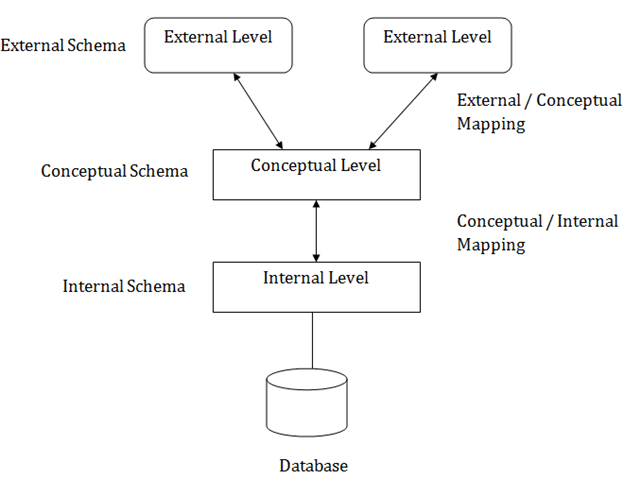 https://www.javatpoint.com/dbms-three-schema-architecture |
Levels

|

|
 https://www.javatpoint.com/dbms-three-schema-architecture
https://www.javatpoint.com/dbms-three-schema-architecture
|
- External: 사용자한테 표기되는 부분이다. 사용자에 따라 보여지는 부분이 다를 것이고, 실제 DB를 직접 보여주는 것이 아니기 때문에 보안이 된다. 사용자 단계
- Conceptual: DB 구조, 데이터 간의 관계를 설명하는 layer. DB 하나에 Conceptual Scehma도 하나이다. 개발자 단계
- Internal: 데이터가 어떻게 저장되어야 하는지를 정의한다. 설계자 단계
Mappings
각각을 연결시켜주는 mapping이 필요하다.
- External / Conceptual Mapping: External에서 conceptual로 접근하는 request를 변환해준다. Conceptual Data Independence. 사용자한테 보여주는 부분과 연결되기 때문에 어렵다.
- Conceptual / Internal Mapping: C에서 I로의 request를 변환. Physical Data Independence. 데이터 보관 offset이 변하더라도 conceptual level schema는 변하지 않아야 한다. 위와 비교적으로 쉽다.
참고
- https://www.javatpoint.com/dbms-three-schema-architecture
함수 종속
변수 $y$와 $x$가 있어서 $y = f(x)$일 때 $x$는 독립, $y$는 종속이다. 하나를 알면 다른 하나도 알 수 있는 것이라고도 표현할 수 있다. 함수 종속성도 이와 마찬가지이다. 속성(attributes) 간의 관계로, 주로 PK와 non-key 사이에 대한 내용이다. X를 결정자(determinant), Y를 종속 속성(dependent)라고 한다.
규칙들
- subset: $A \subseteq B$ 이면 $B → A$ (trivial. 마찬가지로 $A $rarr; A$도 trivial)
- augmentation/증가: $A → B$이면 $AC → BC$
- transitivity/이행: $A → B$, $B → C$면 $A → C$
- union: $A → B$, $A → C$일 때 $A → BC$
- decomposition: union의 반대
- pseudotransitivity: 증가규칙과 이행규칙 결합. $A → B$, $DB → C$면 $DA → C$
그래서 이것을 왜 알아야 하느냐 하면 함수종속성으로 인해 이상현상이 발생하기 때문이다. 삭제이상, 삽입이상, 수정이상이 있다.
- 삭제이상: 하나를 삭제했을 때 다른 정보까지 삭제가 이루어진다
- 삽입이상: 값을 삽입할 때 특정 속성에 NULL을 입력해야 한다
- 수정이상: 값을 수정할 때 중복 데이터 중 일부만 수정되어 불일치가 발생한다.
이를 해결하기 위해 정규형을 알아야 한다.
- 1NF: atomicity. 하나의 속성은 하나의 value를 가져야 한다. 즉 comma-separated 형식으로 여러 값을 가져서는 안 된다. 이를 분해해서 여러 개의 record로 나누어야 한다. 그래도 부분종속인 속성들이 있기 때문에 이상현상 발생한다.
- 2NF: non-prime 속성이 primary key에 완전 종속적이어야 한다. 즉 다른 속성(candidate key)에 종속되는 부분이 없어야 함. 이행적 함수 종속성이 있기 때문에 이상현상이 발생한다. 즉 $A → B$, $B → C$면 $A → C$
- 3NF: 위를 해결하여 primary key 이외의 속성이 다른 속성을 결정할 수 없도록 분해한다. 그래도 결정자를 후보키로 취급하지 않는다면 이상현상이 발생한다.
- BCNF: 모든 결정자를 항상 후보키가 되도록 분해한다면 이전에 발생한 이상현상을 해결할 수 있다.
key에 대해서 좀 정리 할 필요가 있을 것 같다.
- primary key: 하나의 구별된 측정 단위를 나타낼 수 있는 고유 값.
- composite/concatenated key: 하나의 구별된 측정 단위를 나타랠 수 있는 composition. 예를 들어 성과 이름은 각각 중복이 있지만 풀네임은 중복이 없다면 풀네임이 composite key가 된다.
- candidate key: primary key를 포함하여 측정 단위를 구분할 수 있는 후보군. 여러 column들이 candidate key가 될 수 있는데, 이 중 하나만 primary key이다.
- alternate key: 후보키를 지정하고 남은 키
- super key: 유일성을 만족하는 셋. 이 키로부터 측정 단위를 구분할 수 있다.
셋이라고 한다면 이름+주소의 composite으로 유일한 키를 만들어낼 수 있다.
참고
- https://rebro.kr/160
- https://jerryjerryjerry.tistory.com/49
- https://rachel921.tistory.com/29
Database Optimizer
쿼리문을 실행할 때 어떻게 하면 효율적으로 실행할 수 있을지에 대한 계획을 세우는 엔진. 계획별 비용을 비교해서 최고 효율의 계획에 따라 쿼리를 수행한다. 크게 규칙 기반과 비용 기반으로 옵티마이저로 나눌 수 있다고 한다.
- https://coding-factory.tistory.com/743
DB index
데이터베이스 내 테이블 검색속도를 향상하기 위한 자료 구조. 인덱스를 사용하지 않는다면 조회하기 위해 전체를 테이블을 탐색해야 한다. 인덱스를 활용한다면 다음의 추가 작업이 있다.
- INSERT: 새로운 데이터에 인덱스 추가
- DELETE: 삭제할 데이터의 인덱스 사용 안 할 것
- UPDATE: DELETE then INSERT의 개념
그런데 꼭 장점만 있는 것은 아니다. 인덱스를 관리하기 위한 공간도 필요하고, 관리를 위한 작업이 있어야 한다. 또 잘못 설정한다면 성능이 떨어질 수 있다.
CREATE INDEX my_index ON my_table(my_id)
CSV 사용
이제까지 사용해보았던 pandas를 그대로 사용할 수도 있겠고, import csv를 해볼수도 있다. csv 모듈이 더 빠르다고 함.
Documentation을 보면 잘 나와있다.
과제 중에 csv 파일을 db 테이블로 가져오는 것이 있었는데 제출할 때는 pandas를 이용했었다. 이를 csv로 적어보자면 다음과 같이 할 수 있을 것이다.
# conn
cur = conn.cursor()
sql_insert_csv = f'''
INSERT INTO passenger VALUES {str(tuple([r'%s']*9)).replace("'", '')}
'''
import csv
with open ('example.csv', newline='') as file:
reader = csv.reader(file, delimiter=',')
for idx, row in enumerate(reader): cur.execute(sql_insert_csv, (idx, *row))
댓글남기기