
AIB 섹션 5 컴퓨터공학 N531 Hash Table
컴퓨터에서 이진으로 나열되어 있는 것들을 어떻게 해석할 것인가
- 데이터를 활용할 때 파이썬 딕셔너리 개념을 얼마나 활용하는지?
- 속도랑 상관 없이 간편한 이름(키)으로 값(밸류)을 저장하고 조회하기 위해 사용했음.
- 어떤 문제점이 있었는지?
- 자료 형태 변환에 있어서 키와 밸류에 혼동이 올 때가 있음.
- 해시 테이블 작동 원리, 해시함수, 해시충돌, 해시테이블 가득 차면?
- 해시테이블은 해시함수를 통해 키를 변환시켜서 결과값을 인덱스로 삼아 값을 저장한다. 이상적인 해시함수는 키에 대응하는 결과값이 전부 다름. 해시함수는 기본적으로 동일한 키에 대해 동일한 해시값을 반환해야 함. 서로 다른 키에 대해 동일한 해시값이 반환되면 해시 충돌이 일어났다고 함. 이를 해소하기 위해 1. 다른 해시 함수 2. 체이닝으로 해당 버킷(해시 array) 슬롯에 동일한 해시값의 밸류를 연결(연결리스트) 3. 오픈 애드레싱(특정 크기의 메모리 공간을 마련해서 충돌하는 해시/밸류를 보관하다가(빈 공간을 찾는 탐사. probing이라고 함) 어느 정도 차면 공간 늘려서 테이블 재구성)
파이썬에서 딕셔너리는 키로 밸류를 조회
해시테이블: 키를 활용하여 값에 직접 접근이 가능한 구조. 그 테이블에서 값 조회. 키를 통해서 밸류를 조회하기 때문에 데이터 양에 영향을 덜 받아 좀 더 빠르다.
해시 함수를 통해서 나온 값인 해시. 함수는 여러 키를 분할하기 위해 해시값으로 매칭시키는 역할을 한다. 그래서 해싱으로 키를 흩뜨려놓고 키와 매칭되는 값을 검색한다.
해시함수는 하나의 키에 대해 하나의 해시값이 나와야 한다. 여러 키에 대해 하나의 해시값이 나오면 해시 충돌.
해시테이블은 충돌만 없다면 $O(1)$ 시간복잡도 안에 검색, 삽입, 삭제를 할 수 있다.
최적화: 해시테이블의 성능을 높이기 위해 무엇을 할 수 있을까
- 더 적절한 해시 함수 선택으로 충돌 최소화
- 충돌을 우회하는 방법으로 체이닝 / 오픈 어드레싱/애드레싱
해시 충돌
실제로 완벽한 해시함수를 만들기는 불가능하기 때문에 충돌을 최소한으로 하는 함수를 만들어야 한다.
체이닝
충돌하는 해시가 있다면 연결리스트로 충돌한 것의 해시값을 연결한다. 저장 공간이 이미 정해져 있지 않음.
버킷: 하나의 해시값. 이 대응되는 모든 key/value가 연결리스트가 들어간다고 생각하기.

오픈 어드레싱
빈 array의 위치를 검색해서 거기에 넣는다. 저장 공간이 이미 정해져 있음. 그래서 부족할까 하는 부분이 있음. 다 차면 다시 해싱한다.
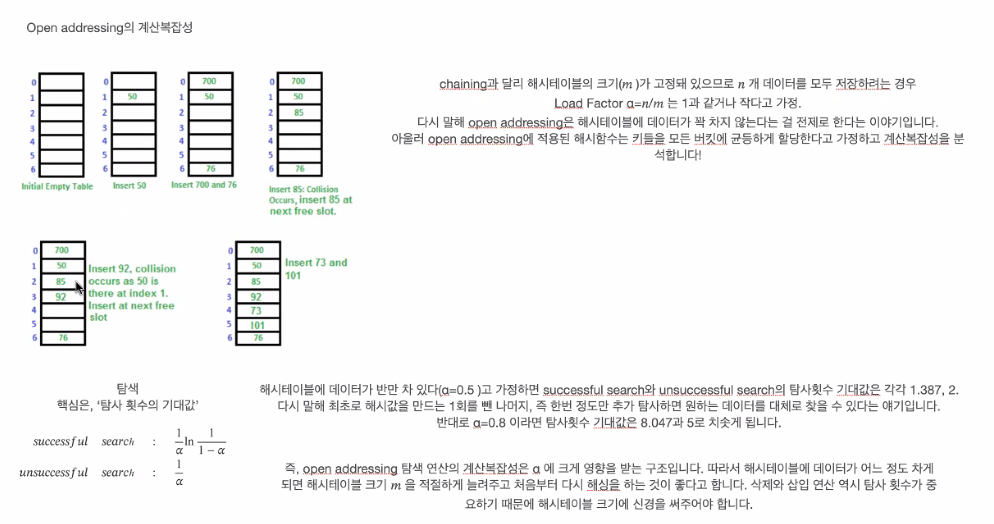
다른 자료 찾아보면 설명 잘 되어 있는데, 해시 공간 찼으면 다른 빈 공간을 찾는다.
먼젓번에 찬 해시 키 밸류를 지운 다은 충돌 했었던 해시키를 다시 찾으려고 하면 없기 때문에 오류가 난다. 별도로 주변을 probe 하라는 flag가 필요함.
파이썬의 딕셔너리
오픈 어드레싱을 활용한다. 빈 공간이 없으면 시간이 오래 걸릴 수 있어서 로드 팩터를 작게 설정하여 해결하고자 한다.
로드 팩터: $\rm{load\ factor} = \frac{\rm{num\ items}} {\rm{num\ slots}}$. 이 비율에 따라 해시탐수를 재작성하던지 해시테이블 크기를 조정하는지 결정한다.
direct-address table
키의 전체 개수와 동일한 크기의 버킷을 가진 해시테이블. 즉 가능한 모든 해시 키와 동일한 크기. 매우 비효율적.
실제 해시 테이블 구현
해시값을 생성할 해시함수를 마련해야 한다. 즉시 활용 가능한 예시로는 sum('key'.encode()) % table_len 또는 별도 라이브러리에서 해시 함수를 가져오면 되겠다.
# shallow copy 방지를 위해 for
table = [[()] for _ in range(10)]
def hash_func(key):
# encode하면 각 byte가 있을텐데 sum하고 mod table size
return sum(key.encode()) % len(table)
def add_item(key, value):
# key.encode()할 때 key는 str만 가능
hash = hash_func(str(key))
# 체이닝 기법 활용을 위해 enumerate idx
for idx, kv in enumerate(table[hash]):
# pair 있고 pair의 key 값이 입력받은 key값과 일치하면
if kv and kv[0] == key:
# 현재 pair override
table[hash][idx] = key, value
break
# break되지 않으면 조회된 pair 없는거라서 새로 추가
else:
# 충돌했으면
if kv:
# append
table[hash].append((key, value))
# 충돌 안 했으면
else:
# 새로 추가
table[hash][0] = key, value
def search_item(key):
hash = hash_func(str(key))
# 마찬가지로 enumerate
for idx, kv in enumerate(table[hash]):
# 키 위치의 값이 입력받은 키와 동일하면
if kv[0] == key:
# 그 키의 밸류 반환
return table[hash][idx][1]
return None
해시테이블을 이용해서 주어진 리스트의 중복 요소들을 제거할 수 있다. set도 내부적으로 해시를 이용하고 있어서 실제 사용에 있어서는 이 내장함수를 이용할 수 있는데, 직접 해시테이블을 구성해본다면 각각의 operation에 대해 시간복잡도가 1인 것을 확인해볼 수 있다.
댓글남기기